 Free Consultation
Free Consultation



Extrapolate, according to its definition, is the process of applying (a method or conclusion) to an unknowable situation by making the assumption that current trends will continue or that similar procedures will be appropriate. When an application is tested in a scaled-down environment with fewer users, extrapolation is necessary for performance testing. A suitable load is applied according to the scaled-down environment server’s capacity, and the findings are then extended to production servers. The “Extrapolation Method” is the name of this technique.
Based on the performance of the test server, the extrapolation method forecasts the capacity of the production server. The price of a completely scaled performance test environment is out of reach for many clients. Therefore, they either request that the test be run in a 50% scaled-down environment or use a single server instance. In this situation, a performance tester must run the test in the given environment with reduced resources. One crucial thing to keep in mind is that all server resources should be scaled down uniformly. The results should also be extrapolated using the same method and math. The erroneous extrapolation result could be caused by an unequal ratio or by using various methodologies.
How is the extrapolation method applied?
Before doing the test and using the extrapolation method, consider the following points:
- Finalize the application’s fundamental tuning.
- Locks, sockets, connection pools, and thread pools are not software bottlenecks.
- There is no network performance issue or network bandwidth issue.
- There should be a ratio between the production and test environment configurations.
Example: In production, there are four Web servers, two app servers, and two database servers. The test environment should then have a subset of 1 app server, 2 Web servers, and 2 DB servers.
gold
Consider deploying the application infrastructure in a single “leg”; For example, if there are 3 web servers, 3 app servers, and a DB cluster, configure 1 web server, 1 app server, and the DB cluster. You could conceivably accomplish this with any portion of the complete deployment model. However, it is preferable to carry out this using the lowest feasible subset.
- JVM heap memory needs to be proportional.
- The test and production servers’ log settings must be identical.
- In the test environment, which should have the same scaled-down ratio as the production environment, check the connection limitations of all the servers.
In general, the linear regression method is effective for extending a roughly linear function to locations close to existing data points in many real-world applications. The method may produce a greater inaccuracy for predicting outcomes that are further from the available data points, though. Its benefits include ease of use and computational simplicity. Since the past trend is assumed to continue into the future using linear regression, the whole information about the data trend is embedded in both the past and present data series. This, however, does not account for any restrictions or conditions from the outside world. The historical trend of the data series does not continue if it fails due to specific circumstances.
Approach for the linear extrapolation method:
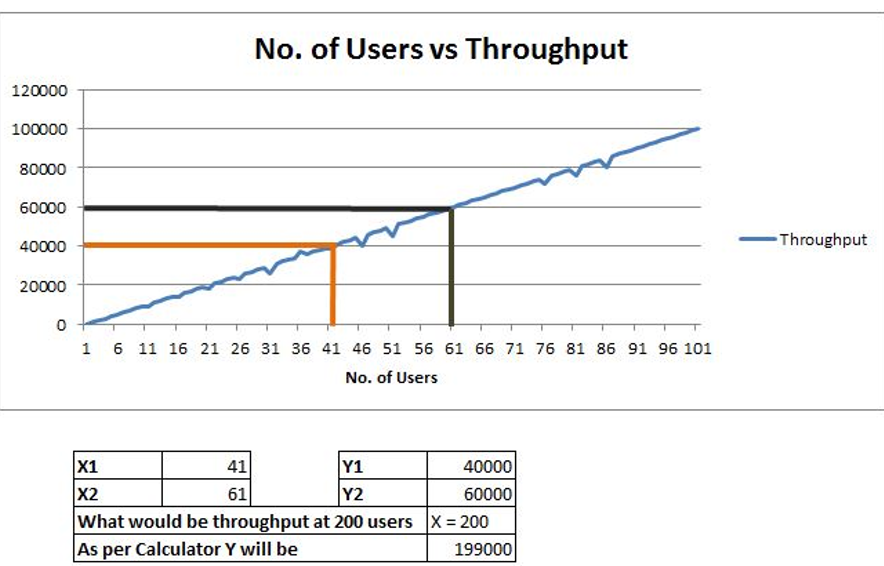
At least two sets of results are needed for the linear extrapolation approach. The accuracy of the forecast result increases with the number of sets of results. You must first create a step-up test scenario and run the test. There are two options: either you can set up numerous load augmentation phases in the same test or you can run multiple tests while gradually increasing the load in each test. Now run the test(s) that best fit your needs to obtain the results.
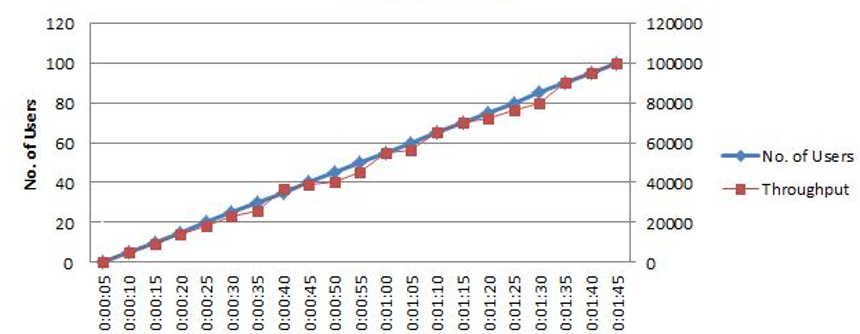
Let’s use one instance to more clearly understand the extrapolation method in practice. I ran a test in which the load was steadily increased. The throughput increased linearly with the number of concurrent users before a system hit a bottleneck. In such a case, the number of pages delivered to each user by the server would increase, resulting in a linear increase in overall throughput. This suggests that, up until a bottleneck occurs in the system, linear extrapolation is a clear choice for projecting the throughput. I recorded the throughput at two different levels of load in order to estimate what it would be at 200 users.
Advice:
- Linear extrapolation can be used for throughput, hits per second, TPS, Java Heap Size, and other metrics.
- It is preferable to employ S-curves or the Mixed mode approach for Response Time, Latency, CPU Utilization, and Memory Utilization.
Conclusion: It is false to state categorically that if a server can handle 500 users with half of its production configuration, it can handle 1000 users with its full configuration. Even with a moderate user load, a report like this runs the danger of causing the entire production system to crash. Consequently, if you run the test in a smaller environment, you will
 We are Online | Privacy policy
We are Online | Privacy policy